이상치 탐지(Anomaly Detection) - Overview

이상치 탐지는 데이터 분석과 기계학습 분야에서 중요한 주제 중 하나로, 데이터에서 이상한 패턴이나 값들을 식별하는 과정을 의미합니다. 이상치는 데이터 분석의 정확성과 안정성을 저해할 수 있기 때문에 그 중요성이 더욱 커집니다.
이상치 탐지: 데이터 분석의 핵심
데이터 분석은 현대 비즈니스 및 연구 분야에서 핵심적인 역할을 합니다. 데이터는 다양한 분야에서 수집되며, 이를 분석함으로써 중요한 의사결정을 내릴 수 있습니다. 그러나 데이터에는 종종 이상치가 포함되어 있을 수 있으며, 이러한 이상치는 정확한 분석을 방해할 수 있습니다. 이상치는 다양한 형태로 나타날 수 있으며, 이러한 이상치를 식별하고 처리하는 것은 데이터 분석가나 기계학습 엔지니어에게 중요한 작업입니다.
이상치란 무엇인가?
이상치란 주어진 데이터 집합 내에서 다른 값들과 현저하게 다른 값을 가지는 데이터 포인트를 가리킵니다. 데이터 집합에서 다른 데이터 포인트와 크게 다른 값을 가지는 데이터를 나타냅니다.
- Positive Outliers: Positive 이상치는 대부분의 데이터 포인트보다 큰 값을 가지며, 종종 예외적으로 우수한 성과나 긍정적인 결과를 나타냅니다. 예를 들어, 급증한 매출 또는 우수한 고객 리뷰는 양적인 이상치의 예입니다.
- Negative Outliers: Negative 이상치는 대부분의 데이터 포인트보다 작은 값을 가지며, 종종 문제나 오류를 나타냅니다. 예를 들어, 부정적인 고객 리뷰, 결함이 있는 제품, 또는 잘못된 거래는 음적인 이상치의 예입니다.
이상치는 종종 오류나 잡음의 결과일 수도 있지만, 때로는 중요한 정보를 제공하기도 합니다. 예를 들어, 금융 분야에서 이상치는 사기 거래의 징후일 수 있으며, 제조업에서는 기계 고장을 나타낼 수 있습니다. 그러나 이상치는 주로 데이터 분석 과정에서 부정확한 결과를 초래할 수 있기 때문에 신중하게 다루어져야 합니다.
이상치와 노이즈
간혹 이상치와 노이즈를 혼동하는 경우가 있습니다. 이상치와 노이즈는 데이터 분석 및 처리에서 서로 다른 개념입니다. 이상치는 데이터 집합 내에서 다른 데이터와 현저하게 다른 값을 가지며, 주로 예외적인 상황을 나타냅니다. 노이즈는 측정 과정에서의 무작위성에 기반하여 무작위 또는 무의미한 변동성으로 데이터의 정확성을 감소시킬 수 있습니다.
이상치는 정상적인 데이터를 생성하는 매커니즘을 위반하여 생성된 주 관심사이며 식별 및 처리가 중요합니다.
이상치 탐지의 중요성
이상치 탐지는 다양한 분야에서 중요한 역할을 합니다. 몇 가지 예를 살펴보겠습니다.
1. 금융 분야
금융 기관은 이상치 탐지를 사용하여 사기 거래를 식별하고 예방합니다. 신용 카드 거래나 은행 거래 내역에서 이상한 패턴이나 금액을 감지함으로써, 사기 행위를 조기에 차단할 수 있습니다.
2. 제조업
제조업에서는 기계의 고장을 미리 예측하고 예방하기 위해 센서 데이터를 사용하여 이상치를 탐지합니다. 기계 고장은 생산 중단을 초래할 수 있으므로, 미리 조치를 취함으로써 비용을 절감할 수 있습니다.
3. 의료 분야
의료 분야에서는 환자의 건강 데이터를 모니터링하고, 이상치를 식별하여 질병의 조기 진단 및 치료에 도움을 줍니다.
이상치 탐지 방법
이상치 탐지를 위한 여러 가지 방법이 존재합니다. 그 중 몇 가지 방법을 간략히 살펴보겠습니다.
1. 기초 통계량 방법
평균, 중간값, 표준편차 등의 기초 통계량을 사용하여 이상치를 식별하는 방법입니다. 주어진 데이터 포인트가 기초 통계량에서 현저하게 벗어나면 이상치로 간주됩니다.
2. 기계학습 기반 방법
기계학습 알고리즘을 사용하여 데이터의 패턴을 학습하고, 그 패턴으로부터 벗어난 데이터를 이상치로 식별합니다. 이상치 탐지에 사용되는 기계학습 모델로는 Isolation Forest, One-Class SVM, 로버스트 이상치 탐지 등이 있습니다.
3. 규칙 기반 방법
도메인 지식을 기반으로 규칙을 정의하고, 데이터가 이러한 규칙을 어길 경우 이상치로 간주하는 방법입니다. 이 방법은 특정 분야에서 유용할 수 있습니다.
이상치 탐지는 데이터 분석과 기계학습 분야에서 중요한 주제로, 데이터의 정확성과 안정성을 유지하기 위해 필수적입니다. 적절한 이상치 탐지 방법을 선택하고 적용함으로써, 데이터로부터 유용한 정보를 추출하고 비즈니스 및 연구 분야에서 더 나은 결정을 내릴 수 있습니다. 이상치 탐지는 신중하고 전략적으로 접근해야 하는 과정이며, 데이터 분석가들에게 중요한 도구 중 하나입니다.
분류 (Classification)와 이상치 탐지 (Anomaly Detection)
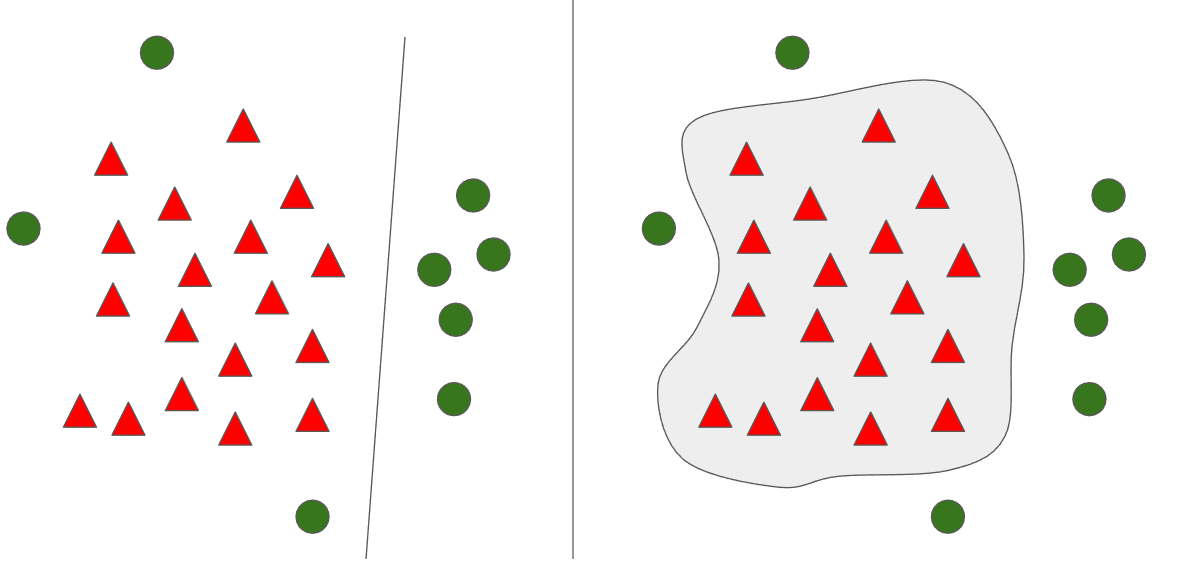
위 그림에서 분류와 이상치 탐지를 구분한다면 왼쪽이 분류이고 오른쪽 그림이 이상치 탐지입니다. 이상치 탐지와 분류는 데이터 분석의 다른 측면을 다루며, 목적, 데이터 라벨링, 사용되는 방법, 결과 등에서 큰 차이가 있습니다. 이상치 탐지는 데이터 집합 내의 이상치를 식별하는 데 중점을 두고 비지도 학습 방법을 사용합니다. 반면, 분류는 데이터를 사전 정의된 클래스 또는 라벨로 분류하기 위해 지도 학습 방법을 사용합니다.
이상치 성능 측정 방법
이상치 탐지 성능을 측정하고 평가하는 데 사용되는 여러 가지 메트릭이 있습니다. 이러한 메트릭은 이상치 탐지 모델의 품질을 평가하고 모델의 성능을 개선하는 데 도움이 됩니다. 아래는 주요한 이상치 탐지 성능 측정 방법입니다
- 정확도 (Accuracy) : 정확도는 모델이 올바르게 분류한 이상치와 정상치의 비율을 나타냅니다. 일반적으로 정상치가 이상치보다 훨씬 많을 때, 정확도는높을 수 있지만 모델의 성능을 정확하게 나타내지 않을 수 있습니다.
- 정밀도 (Precision) : 정밀도는 모델이 이상치로 분류한 데이터 중에서 실제로 이상치인 비율을 나타냅니다. 즉, "모델이 이상치로 분류한 것 중에서 얼마나 많이 실제로 이상치인가?"를 측정합니다.
- 재현율 (Recall) : 재현율은 실제로 이상치인 데이터 중에서 모델이 정확하게 이상치로 분류한 비율을 나타냅니다. 즉, "모델이 이상치로 분류해야 하는 것 중에서 얼마나 많이 실제로 이상치로 분류했는가?"를 측정합니다.
- F1 점수 (F1 Score) : F1 점수는 정밀도와 재현율의 조화 평균을 나타냅니다. F1 점수는 정밀도와 재현율 간의 균형을 나타내며, 모델의 전반적인 성능을 평가하는 데 유용합니다.
- ROC 곡선과 AUC (Receiver Operating Characteristic Curve and Area Under the Curve): ROC 곡선은 모델의 민감도(재현율)와 특이도(1-거짓 양성 비율) 사이의 관계를 시각화한 것입니다. AUC는 ROC 곡선 아래의 면적으로, 모델의 전반적인 성능을 나타냅니다. AUC가 높을수록 모델의 성능이 우수합니다.
- PR 곡선과 AUC (Precision-Recall Curve and Area Under the Curve) : PR 곡선은 정밀도와 재현율 사이의 관계를 시각화한 것입니다. PR AUC는 PR 곡선 아래의 면적으로, 불균형 데이터셋에서 모델의 성능을 평가하는 데 유용합니다.
- 이상치 점수 (Outlier Score) : 이상치 탐지 모델은 각 데이터 포인트에 대한 이상치 점수를 생성합니다. 이 점수를 사용하여 이상치의 상대적인 정도를 평가할 수 있습니다.
- Confusion Matrix (혼동 행렬): 혼동 행렬은 모델의 예측 결과와 실제 데이터 간의 관계를 보여줍니다. 이를 통해 정확한 예측, 오류, 거짓 양성 및 거짓 음성을 측정할 수 있습니다.
이상치 탐지의 성능 측정은 문제의 복잡성, 데이터의 특성, 목표와 관심사에 따라 다를 수 있습니다. 따라서 적절한 메트릭을 선택하여 모델을 평가하고 개선하는 것이 중요합니다.