[MLflow] #3. MLflow Model 정리하기
MLflow 플랫폼은 크게 MLflow Tracking, MLflow Projects, MLflow Model, MLflow Model Registry의 컴포넌트로 구성된다.
이 글에서는 그 중 MLflow Models 기능에 대해서 정리한다. MLflow Models 의 기본적인 기능은 아래와 같다.
MLflow Model
- 머신러닝 모델을 패키징하고 서빙할 수 있는 표준화 방법 제공
- 동일한 모델을 AWS, Apache Spark 등 으로 쉽게 배치할 수 있도록 지원
- 다양한 다운스트림 도구(예: REST API를 통한 실시간 제공 또는 Apache Spark의 추론)에서 사용할 수 있는 기계 학습 모델을 패키징하기 위한 표준 형식
- 이 형식은 모델을 다른 하위 도구에서 이해할 수 있는 다양한 "flavor(풍미)"로 저장할 수 있도록 정의된 규약을 제공한다.

모델은 다양한 도구를 사용하여 생성될 수 있으며 다양한 환경에서도 생산되고 배포될 수 있다. 이러한 환경은 확습환경과 다를 수 있다. M개의 프레임워크를 N개의 여러 배포환경에 매핑하는 문제를 해결하기 위해 MLflow Model 이란 추상화 모델을 사용한다.
MLflow Model의 구성
MLflow Model은 다음과 같은 요소로 구성되어 있다.
- 패키징 포맷
- MLmodel 파일이 포함된 특정 디렉토리 구조
- 학습코드가 아닌 직렬화된 모델 아티팩트를 포함한다.
- 재현성을 위한 의존성 항목 집합
- 다른 환경에서도 동일하게 사용할 수 있도록 프로젝트의 의존성 항목의 집합이 포함된다.
- 예를들어 Conda 환경 등이 MLmodel 설정에 명시된다.
- 유틸리티 API
- 모델 직렬화를 위한 생성, 저장, 로드등을 위한 유틸리티
- mlflow.<model_flavor>.save_model()
- mlflow.<model_flavor>.log_model()
- mlflow.<model_flavor>.load_model()
- 모델 직렬화를 위한 생성, 저장, 로드등을 위한 유틸리티
- 배포 API
- 모든 MLflow 모델을 다양한 서비스에 생성하고 배포하는 API
- CLI / Python / R / Java 지원
저장 포맷
개발한 모델을 다른 연구자 또는 개발자에게 공유하고, 다른 시스템에 서빙하기 위해서는 정보가 저장된 형태여야 하고, 이런 표준화된 저장 포맷으로 해당 기능을 제공할 수 있다. 각 MLflow Model은 루트에 있는 ML Model 파일과 함께 임의의 파일을 포함하는 디렉터리이다. 이 디렉터리에는 머신러닝 모델을 볼 수 있는 여러 특징을 정의할 수 있는 정보가 포함되어 있다.
$Flavor$ 는 MLflow 모델을 강력하게 만드는 핵심 개념이다. $Flavor$는 배포 도구가 모델을 이해하는 데 사용할 수 있는 규칙으로 각 도구를 각 라이브러리와 통합하지 않고도 모든 ML 라이브러리의 모델과 함께 작동하는 도구를 작성할 수 있다. $Flavor$는 python 라이브러리와 더불어 여러 라이브러리를 지원하고 있다. 이런 라이브러리를 사용하면 여러가지 일들을 할 수 있는데, 파이프라인을 통해 모델을 서빙하기 위한 형태로 만들거나, 모델 자체를 로드할 수도 있다.
이런 특정 모델이 지원하는 모든 $Flavor$은 YAML 형식의 MLmodel 파일에 정의된다. 예를 들어 mlflow.sklearn은 모델을 다음과 같이 출력합니다.
# Directory written by mlflow.sklearn.save_model(model, "my_model")
my_model/
├── MLmodel
├── model.pkl
├── conda.yaml
├── python_env.yaml
└── requirements.txtmlflow.sklearn.log_model(...) 로 생성한 MLmodel 파일 내에는 다음과 같은 정보들이 포함되어 있다. MLmodel 파일 내에 $Flavor$가 있는 것을 볼 수 있다.
time_created: 2023-04-2T12:21:23.12
flavors:
sklearn:
sklearn_version: 1.2.0
pickled_model: model.pkl
saved_model_dir: estimator
python_function:
loader_module: mlflow.sklearn위에서 생성한 MLmodel 파일에는 두 개의 $Flavor$ (sklearn, python_fuction)이 명시되어 있다. 각 $Flavor$ 는 번들형태로 묶여져 명시된다.
MLflow Model Flavor 예제
예제를 통해 Flavor가 어떻게 사용되는지 살펴본다. 사용자가 모델을 훈련시키고 MLflow Tracking 을 이용하여 기록한 다음 Model로 저장 및 다시 로드하여 평가하는 예시이다.

- sklearn과 같은 프레임워크를 사용하여 모델을 학습합니다.
- mlflow.sklearn.log_model() 함수를 이용하여 모델을 기록한다.
- 2번 과정을 통해 두 개의 Flavor가 포함된 MLflow Model 형식을 생성한다.
- 첫 번째는 python function flavor
- 두 번째는 sklearn 전용 flavor
- MLflow 모델의 pyfunc를 로드하고 평가할 때 mlflow.pyfunc.load_model() 함수를 사용한다.
- 이 과정은 사용자에게 sklearn 모델에 대해 완벽하게 추상화한다.
- 선택적으로 사용자는 sklearn 전용 flavor를 로드하여 기본 keras 객체를 얻을 수 있다.
MLflow Model 간단히 사용해보기
import mlflow
import pandas as pd
import numpy
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
df = pd.read_csv('./data/raw/diabetes.csv')
df_sub = df.loc[:, ['Pregnancies', 'Glucose', 'BloodPressure', 'Outcome']]
df_train, df_test = train_test_split(df_sub, test_size=0.3, random_state=123)
model = KNeighborsClassifier().fit(X = df_train.iloc[:, :3], y = df_train.Outcome)
eval_data = df_test
with mlflow.start_run() as run:
# Log the baseline model to MLflow
mlflow.sklearn.log_model(model, "model")
model_uri = mlflow.get_artifact_uri("model")
result = mlflow.evaluate(
model_uri,
eval_data,
targets = "Outcome",
model_type = "classifier",
evaluators = ["default"],
)
해당 코드 실행 후 $mlfow ui$ 명령어를 실행하면, 아래와 같이 모델에 대한 내용과 평가 내용에 대해 그래프로 확인할 수 있다.
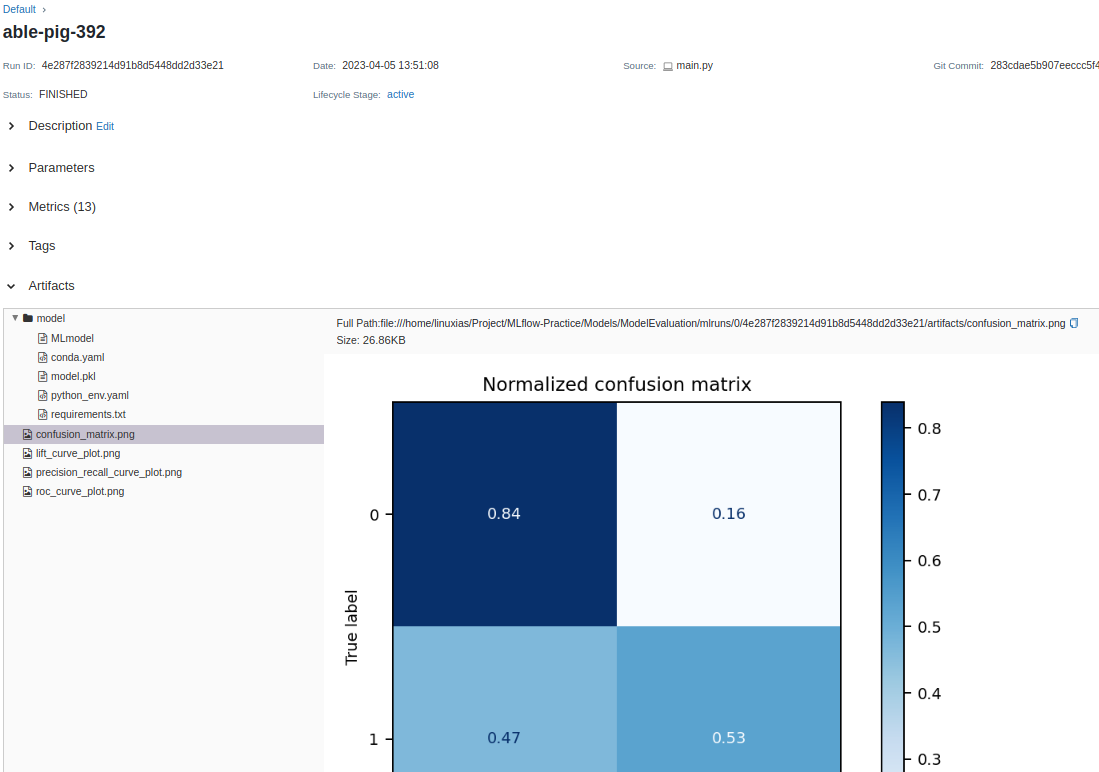
결론
Deply Engineer는 팀 내에서 개발 중인 수많은 모델과 호환되는 이 레이어를 이용하여 관리하기가 매우 쉬워진다.
참고
https://mlflow.org/docs/latest/models.html
https://www.coursera.org/learn/ml-pipelines-google-cloud-ko