AI/Data Science
[Data Science] 서울시 따릉이 이용정보 데이터
Linuxias
2023. 2. 7. 23:28
반응형
데이터과학에서 python을 도구로 사용할 시 pandas, numpy 등의 라이브러리를 떨어질 수 없는 관계이다. 해당 연습을 위해 DataMinim 님의 데이터를 활용하여 연습하고, 결과를 공유하려 한다.
작업 1유형 — DataManim
Question 15 각 비디오는 10분 간격으로 구독자수, 좋아요, 싫어요수, 댓글수가 수집된것으로 알려졌다. 공범 EP1의 비디오정보 데이터중 수집간격이 5분 이하, 20분이상인 데이터 구간( 해당 시점 전,
www.datamanim.com
데이터 다운받기
사용하는 데이터는 DataMinim 님이 정제해둔 데이터이다. 아래와 같이 다운로드 한다.
import pandas as pd
df =pd.read_csv('https://raw.githubusercontent.com/Datamanim/datarepo/main/bicycle/seoul_bi.csv')
df.head()
문제 1. 대여일자별 데이터의 수를 데이터프레임으로 출력하고, 가장 많은 데이터가 있는 날짜를 출력하라
df['대여일자'].value_counts().sort_index().to_frame().idxmax()답안
대여일자 2021-06-04
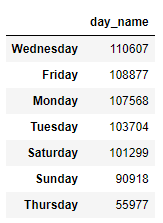
문제 2. 각 일자의 요일을 표기하고 (‘Monday’ ~’Sunday’) ‘day_name’컬럼을 추가하고 이를 이용하여 각 요일별 이용 횟수의 총합을 데이터 프레임으로 출력하라
df.대여일자 = pd.to_datetime(df.대여일자)
df['day_name'] = df.대여일자.dt.day_name()
df.day_name.value_counts().to_frame()답안
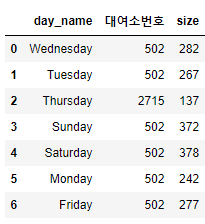
문제 3. 각 요일별 가장 많이 이용한 대여소의 이용횟수와 대여소 번호를 데이터 프레임으로 출력하라
df_sub = df.groupby(['day_name', '대여소번호'] , as_index=False).size()
df_sub = df_sub.sort_values(['day_name', 'size'], ascending = False).reset_index(drop=True)
df_sub.drop_duplicates('day_name', keep='first').reset_index(drop=True)답안
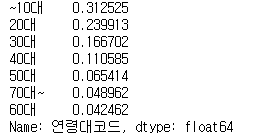
문제 4. 나이대별 대여구분 코드의 (일일권/전체횟수) 비율을 구한 후 가장 높은 비율을 가지는 나이대를 확인하라. 일일권의 경우 일일권 과 일일권(비회원)을 모두 포함하라
df_sub = pd.crosstab(df.연령대코드, df.대여구분코드)
(df_sub['일일권(비회원)'] + df_sub['일일권']) / df_sub.sum(axis = 1)
또는
daily = df[df.대여구분코드.isin(['일일권', '일일권(비회원)'])].연령대코드.value_counts().sort_index()
total = df.연령대코드.value_counts().sort_index()
(daily/total).sort_values(ascending=False)답안
문제 5. 연령대 코드가 20대인 데이터를 추출하고,이동거리값이 추출한 데이터의 이동거리값의 평균 이상인 데이터를 추출한다.최종 추출된 데이터를 대여일자, 대여소 번호 순서로 내림차순 정렬 후 1행부터 200행까지의 탄소량의 평균을 소숫점 3째 자리까지 구하여라
df_20 = df[df.연령대코드 == '20대']
mean_20 = df_20.이동거리.mean()
df_mean_20 = df_20[df_20.이동거리 >= mean_20].reset_index(drop = True)
df_sort = df_mean_20.sort_values(['대여일자', '대여소번호'], ascending=False).iloc[:200, :]
round(df_sort.탄소량.astype('float').mean(),3)답안 : 1.613
문제 6. 평일 (월~금) 출근 시간대(오전 6,7,8시)의 대여소별 이용 횟수를 구해서 데이터 프레임 형태로 표현한 후 각 대여시간별 이용 횟수의 상위 3개 대여소와 이용횟수를 출력하라
df_day = df[df.day_name.isin(['Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Monday', ])]
df_day_time = df_day[df_day.대여시간.isin([6, 7, 8])]
df_sub = df_day_time.groupby(['대여시간', '대여소번호'])['이용건수'].size().to_frame('이용횟수')
df_sub.sort_values(['대여시간', '이용횟수'], ascending=False).groupby('대여시간').head(3)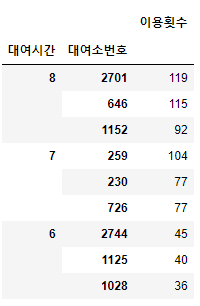
문제 7. 남성(‘M’ or ‘m’)과 여성(‘F’ or ‘f’)의 이동거리값의 평균값을 구하여라
df['sex'] = df.성별.apply(lambda x: '남성' if x in ['m', 'M'] else '여성')
df.groupby('sex', as_index=False)['이동거리'].mean()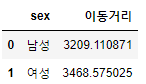
반응형