[데이터 과학] 확률분포 (이산형, 연속형)
확률변수와 확률분포
표본공간에 발생하는 원소를 정의역으로 하고 이에 대응되는 실수값을 치역으로 하는 함수를 확률변수라고 한다. 치역에 해당하는 실수값이 확률을 대응시켜 나타낸 것을 확률분포라 한다.
위 말을 수학적으로 표현하면, 확률변수는 정의역이 표본공간이고 치역이 실수값인 함수이다. 이 때 이 확률변수가 어떤 확률분포에 대응할 때, 우리는 `확률분포에 따른다` 라고 표현할 수 있다.
확률변수의 종류는 다음과 같다.
- 이산형 확률변수 (Discrete random variable) : 확률질량함수라고도 불림
- 확률이 0보다 큰 값을 갖는 점들로 확률을 표현할 수 있다.
- 사건의 확률이 그 사건들(그래프 상의 점들)이 발생하는 확률의 합으로 표현할 수 있는 확률 변수
- 연속형 확률변수 (Continuous random variable) : 확률밀도함수 라고도 불림
- 사건의 확률이 그 사건 위에서 어떤 0보다 큰 값을 갖는 함수의 면접으로 표현되는 확률변수
위의 확률변수에 따라 이산확률분포와 연속 확률분포로 나뉠 수 있다. 두 가지 확률분포에 대해 정리한다.
이산확률분포
이산확률분포는 확률변수가 정수값을 가지는 경우이다. 이산확률분포의 확률변수를 X라 할 때 확률변수가 취할 수 있는 모든 실수들의 집합을 상태공간이라 한다. 이 때 확률변수 X의 상태공간이 유한집합 또는 셀수 있는 무한집합인 경우 이산확률 변수라하고, 이 확률변수 X가 취하는 각 경우에 대한 확률을 표 또는 함수식으로 표현한 것을 확률분포라 한다.
이산확률 분포에는 균등분포, 이항분포, 포아송분포, 초기하학분포, 지수분포 등이 있다. 각 분포에 대해 하나씩 정리한다.
1. 균등분포
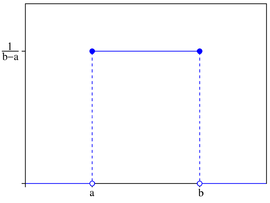
균등분포는 확률분포함수가 정의된 모든 곳에서 값이 일정한 분포이다. 그림에서 나타나듯이 균등분포의 확률 변수는 아래와 같다.
f(x) = 1 / (b - a)
2. 이항분포
이항분포는 베르누이 실험 또는 베르누이 시행에 기초하는 분포이다. 베르누이 시행을 n번 반복하게 되면 이상 실험이 된다.
여기서 베르누이 실험이란 확률실험을 했을 때 결과가 딱 2가지 종류만 나오게 되는 케이스이다. 가장 대표적인 경우가 동전던지기 이다. 그 외에도 다양한 경우가 나오는 것을 이분화하는 방법도 가능하다. 주사위를 던졌을 때 3보다 작은 수가 나올 경우와 아닌 경우로 나뉠 수 있다.
3. 포아송 분포
이항분포가 주어진 횟수의 시행 중에서 사건횟수에 적용되는 분포임에 반하여 포아송 분포는 일정한 단위시간, 단위거리, 단위면적과 같이 어떤 구간에서 어떤 사건이 랜덤하게 발생하는 경우에 사용할 수 있는 있는 이산형 확률분포이다.
포아송 분포는 구간마다 발생하는 사건은 서로 독립적이며 구간의 길이에 따라 사건의 발생 확률이 비례한다. 구간이 길어질 수록 해당 구간 내에서 사건이 발생할 확률이 높아지는 것이다. 그렇기 때문에 반대로 아주 작은 구간에 대해서 사건이 발생할 확률은 무시할만 하다.
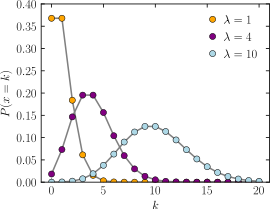
포아송 분포에서 람다가 작은 경우에는 오른꼬리 형태를 띄지만 위 그림과 같이 포아송분포에서 람다가 증가함에 따라 변화에 따라 포아송분포가 정규분포의 형태를 따름을 알 수 있다.
연속확률분포
연속확률분포는 확률변수가 소수점의 값을 포함하는 실수의 값을 가지는 경우이다.
연속확률분포에는 정규분포, 표준정규분포, 지수분포, T-분포, 카이제곱분포, F-분포 등이 있다.
1. 지수분포
지수 분포는 사건이 서로 독립일 때, 일정 시간 동안 발생하는 사건의 횟수가 포아송 분포를 따른다면, 다음 사건이 일어날 때 까지 대기시간은 지수분포를 따른다.
즉 사건이 발생한 이후 다음 사건이 발생할 때까지의 시간이 길면 길 수록 사건이 발생할 확률을 줄어드는 지수 그래프 형태를 띄게된다. 따라서 항상 양의 값을 가지고 있는 형태이다.
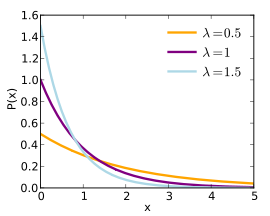
포아송분포와 지수분포는 사건을 바라보는 관점이 다르다. 어떤 단위 시간동안 발생하는 사건을 관찰한다고 했을 때, 사건이 서로 독립적일 때, 일정 시간동안 발생하는 사건의 횟수가 푸아송 분포를 따른다면, 다음 사건이 일어날 때까지 대기 시간은 지수분포를 따른다 이는 기하분포와 유사한 측면이 있다.
2. 정규분포
연속확률변수에 관련하여 하나의 전형적인 분포의 유형으로 연속확률변수를 기술하는 가장 중요한 확률분포이다. 정규분포의 모양과 위치는 분포의 평균과 표준편차로 결정이 된다. 정규곡선은 정규분포의 확률밀도함수에 의해 결정이 되는데 여기서 확률밀도함수는 평균을 중심으로 대칭적인 종모양의 형태를 띈다.
또한 중심극한정리에 의하여 각 표본에서 구한 통계량들의 통계량을 구하게 되면 모집단이 어떤 분포를 가지던지 표본의 통계량에 대한 통계량은 정규분포를 따르게 된다. 이말인 즉, 독립적인 확률변수들의 평균, 분산은 정규분포에 가까워 지는 성질이 있기 때문에 수집된 자료의 분포를 근사하는데에 자주 사용된다는 것이다.
정규분포의 특성은 다음과 같다.
- 종모양
- 평균을 중심으로 좌우대칭형(평균 == 중앙값 == 최빈값)
- 형태와 위치는 평균과 표준편차에 의해 결정된다.
- 정규곡선의 전체 면접은 1이다.
- 평균 주위로 표준편차(σ) 내의 데이터의 68%, 표준편차 * 2 내의 데이터의 95%, 표준편차 * 3 내에 데이터의 99%가 있다.
3. 표준정규분포 (Z-분포)
정규분포에서 추가로 알아야 하는 부분은 표준정규분포이다. 정규분포는 평균과 표준편차에 따라 그 모양과 위치가 달라지기 때문에 서로 다른 두 정규분포의 성격을 비교하거나 확률을 계산하기 위해서는 표준화가 필요하다.
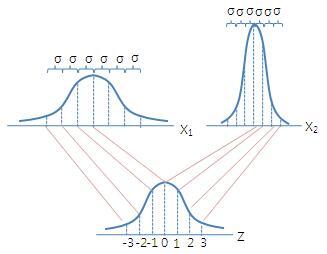
표준화란 어떤 정규분포던 간에 중심(평균)을 0으로 분산을 1로 맞추는 과정을 뜻한다. 표준 정규분포와 정규분포의 공통점은 평균을 중심으로 좌우대칭이고 종 모양을 하는 점이 똑같으며, 전체 면적이 1 이고, 각 σ 만큼의 면적이 변환 전후에도 같다는 것이다.
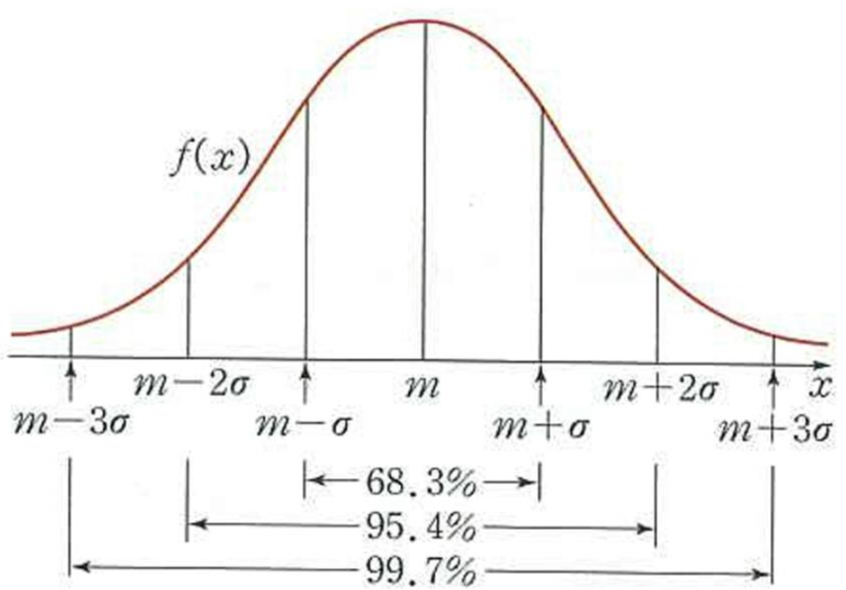
정규분포를 표준화 시킨 분포라고 이해하면 쉽다. 어떠한 정규분포던 간에 중심(평균)을 0으로 분산을 1로 맞추는 것이다. 위에 표준정규분포를 보았을 때 -1.96 ~ 1.96 내에 약 95%의 데이터가 있음을 알 수 있다.
확률밀도함수의 평균과 표준편차의 관계가 표준정규분포의 경우 다음과 같이 나타난다.
P(-1 <= X <= 1) = 0.6829
P(-2 <= X <= 2) = 0.9545
P(-3 <= X <= 3) = 0.9973
4. 카이제곱분포
카이제곱분포(chi-squared distribution, χ2 분포)는 k개의 서로 독립적인 표준 정규 확률 변수를 각각 제곱한 다음 합해서 얻어지는 분포이다.
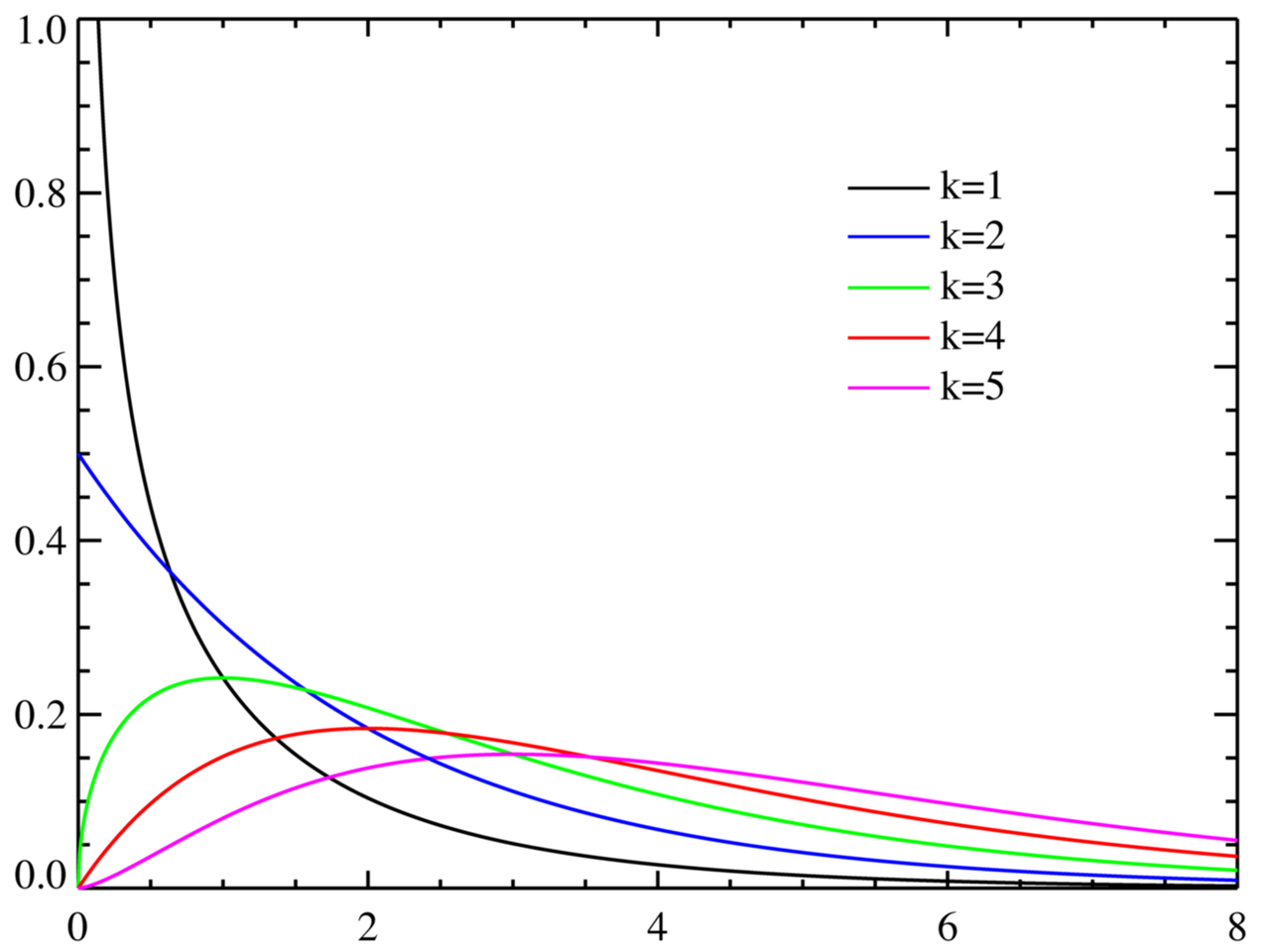
제곱합을 사용하는 이유는 오차 또는 편차를 분석할 때 도움을 받을 수 있기 때문이다. 위 분포를 살펴보면, 카이제곱분포는 자유도에 따라 분포의 모양이 변하는 것을 알 수 있다. 자유도가 클수록 정규분포에 근접하는 특정을 가지게 된다. 또한 제곱합이므로 항상 양수를 가진다.
이러한 카이제곱분포는 모집단 분산을 추론하거나 카이제곱 검정에서 많이 사용된다. 카이제곱검정은 추후에 다루겠지만 해당 검정을 통해 오차가 우연히 발생한 것인지 아니면 숨겨진 의미가 존재하는지 알 수 있는 기준이 된다.
5. T - 분포
6. F - 분포