Loading data from csv file
1. numpy - loadtxt
[source]
Load data from a text file.
Each row in the text file must have the same number of values.
| Parameters: | fname : file, str, or pathlib.Path
dtype : data-type, optional
comments : str or sequence, optional
delimiter : str, optional
converters : dict, optional
skiprows : int, optional
usecols : int or sequence, optional
unpack : bool, optional
ndmin : int, optional
|
|---|---|
| Returns: | out : ndarray
|
2. tensorflow 이용하기
import tensorflow as tf
filename_queue = tf.train.string_input_producer(
['file1.csv', 'file2.csv', 'file3.csv', ..], shuffle=False, name='filename_queue')
#아래 그림과 같이 Reader를 만듬.
reader = tf.TextLineReader()
key, value = reader.read(filename_queue)
# 값이 없는 경우에 Default 값과 Type으로 생성해 줄 부분,
# 현재 4개의 column을 가진 csv 파일들이기에 4개를 float형으로 읽어온다.
record_defaults = [[0.], [0.], [0.], [0.]]
data = tf.decode_csv(value, record_defaults=record_defaults)
# tf.train.batch를 이용해 csv 데이터 읽어오기
train_x_batch, train_y_batch = \
tf.train.batch([xy[0:-1], xy[-1:]], batch_size=10)
# placeholders for a tensor that will be always fed.
X = tf.placeholder(tf.float32, shape=[None, 3])
Y = tf.placeholder(tf.float32, shape=[None, 1])
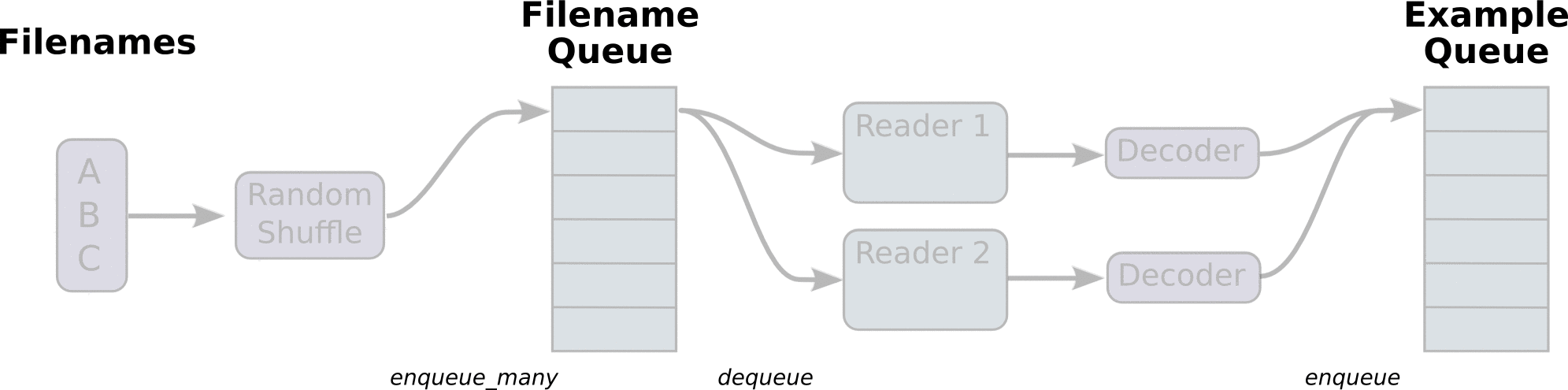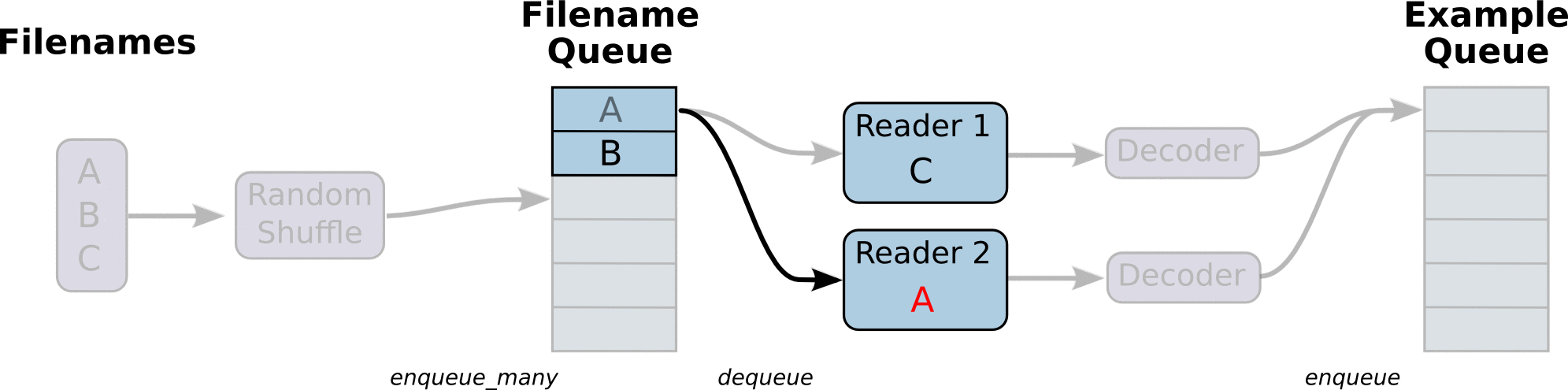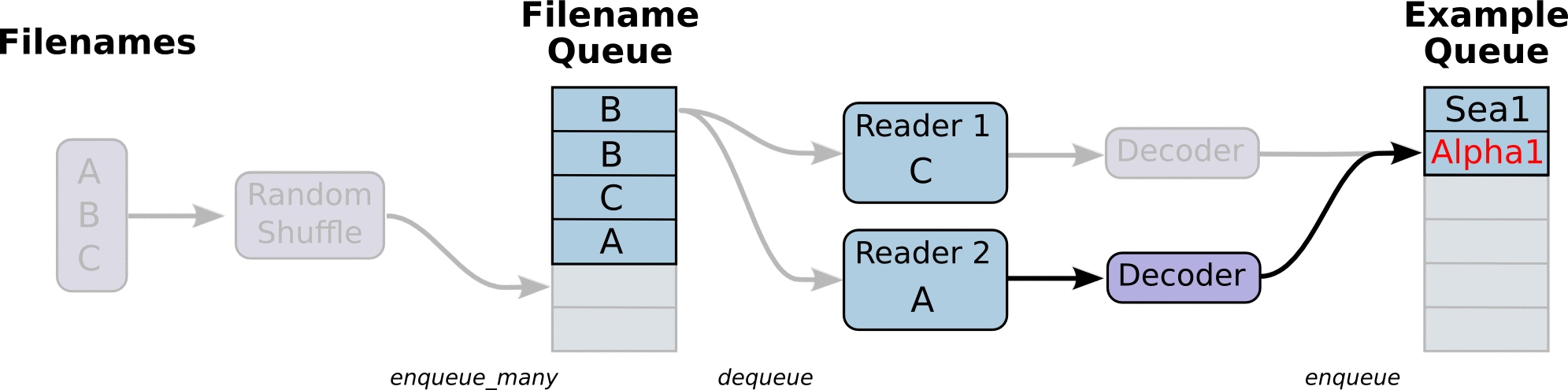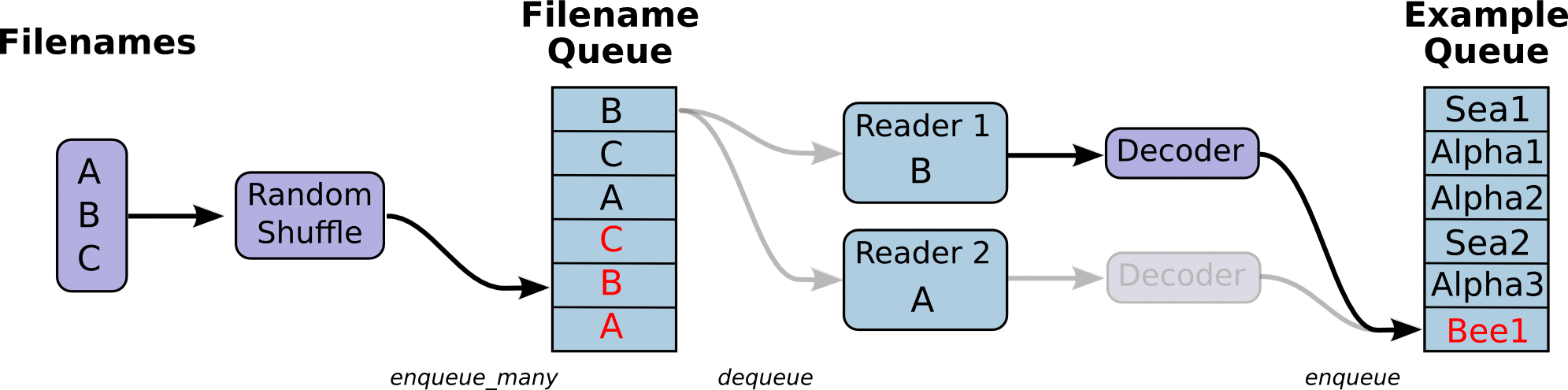
참고 URL
: https://www.youtube.com/watch?v=o2q4QNnoShY
https://www.tensorflow.org/programmers_guide/reading_data